コンピュータを使っているとたまに奇っ怪な日本語に出会うことがあります。 たとえば、Windows NT や Windows 2000 を使っている人は次のようなウィンドウを 見たことがあるかもしれません:
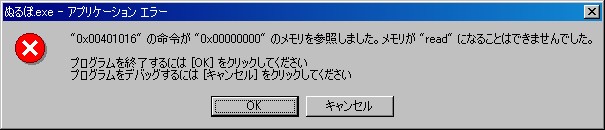
この「メモリが "read" になることはできませんでした」 という文章を初めて見た人は、みんな目が点になると思います。
このコラムは、この「謎の日本語」がどこからやってきたのかを解明しつつ、 国際化/ローカライゼーションの難しさについて考えてみたいと思います。
この変な日本語がどこからやってきたのかを考えてみると、 まず直感的に思いつくのは、 「これは英語メッセージの直訳なのではないか。 そしてその訳が不適切だったのではないか」 という仮定です。このことは、もともと Windows という OS が アメリカ発祥であることと、read という英単語を そのまま使っていることからも正しいのではないかと推測できます。 コンピュータに詳しい人ならば、少しばかり推理を働かせることにより、 このメッセージがメモリ保護違反によって 引き起こされたエラーを通知するもので、 より日本語らしい日本語で言い直せば 「メモリを読むことができませんでした」 という意味になることが理解できると思います。
さて、こうなると、この文の原文がどうだったかが気になるところです。 日本語と英語との間の文法の違いや基礎語彙の包含関係のズレなどによって、 辞書に載っている意味で和訳すると、しばしば珍妙な日本語が生まれます。 逆にいえば、そのクセを見抜ければ元の文を復元できるとも言えます。 そこで、まずは和訳後の和文からもとの英文を推測してみることにします。 「なる」という意味の言葉として日本人にとってなじみの深い英単語は 「become」なので、とりあえずこれを使ってこの文を英語に「直訳」すると、
The memory could not become "read".
となります。しかし、これでは元の日本語と同じ奇っ怪さを持った 英文になってしまいます。 いくらなんでも和訳前のメッセージがこんなアホなメッセージなわけがありません。
ここで謎を解くヒントとなるのは、次のダイアログです:
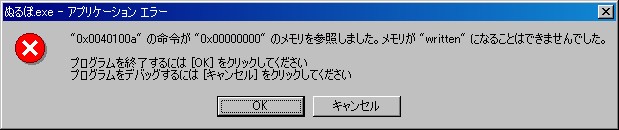
ここでは、「read」の代わりに「written」という単語が使われています。 もうわかりましたか?
日本人はついつい忘れがちなのですが、 「なる」という意味を含んだもっと一般的な動詞があります。 それはいわゆる be 動詞と呼ばれるものです。これを使って英訳すれば、
The memory could not be "read".
となります。 この二重引用符で囲まれた「"read"」という単語を名詞として解釈すれば、 確かに「"read" になれない」という翻訳もできなくはありませんが、 普通はそうは訳しません。つまり、この「read」は過去分詞であり、 全体としては受動態の文章なのです。 直訳すれば、「そのメモリは読まれることができませんでした」となります。 もっと自然な日本語に直すなら、主語を省略した能動態に変えて 「そのメモリを読むことができませんでした」とするべきでしょうね。 これなら意味が通りますし、さきほど述べた 「メモリ保護違反によって引き起こされたエラーの通知」 としての意味とも合致します。
さて、上の仮説は正しいのでしょうか。 これは実際に英語の Windows を入れてみればわかります。 じゃじゃーん:
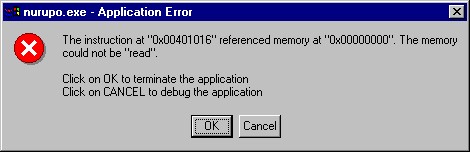
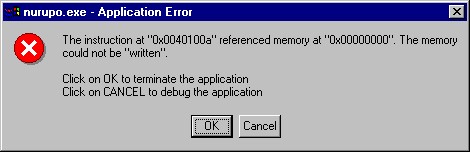
というわけで、まさにそのとおりでした。
さて、これを見てあなたはどう思うでしょうか? 「MS は、なんでこんな中学生でもしないようなアホな間違いをするんだ?」 と思うかもしれません。あるいは、 「MS は、メッセージを機械翻訳に通すだけでチェックをしないという 手抜きをしてるのではなか?」と思うかもしれません。 しかし、本当にこれはアホな間違いなのでしょうか? あるいは本当にこれはそんな単純な手抜きの産物なのでしょうか? 以下では、なんでこんなことになったのか検証してみます。
この件の背景を探るためには、 まず「このウィンドウを誰が出しているのか」を突き止めるところから始めます。 このためには、Visual Studio に付属する Spy++ というツールが便利です。 このツールを起動し、ウィンドウファインダというツールを使うと、 マウスカーソルで指定した任意のウィンドウの各種属性を知ることができ、 この中にはそのウィンドウを所有するプロセスの ID が含まれています。 そして、プロセス ID がわかれば、そこからさらに実行ファイル名もわかります:
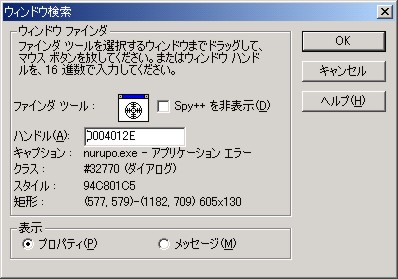
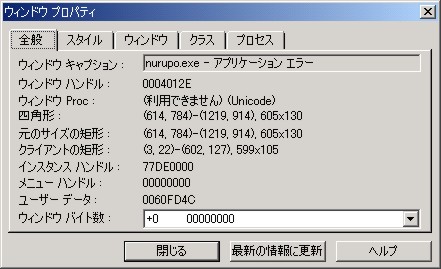
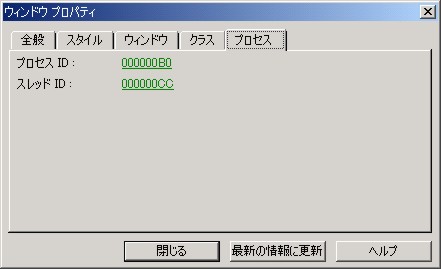
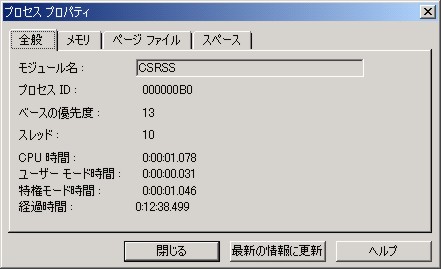
このようにして、このウィンドウを出しているのが CSRSS というモジュールであるということが判明します。
CSRSS.EXE はタスクマネージャで見るといつも常駐しているプロセスです。 その実行ファイルは c:\winnt\system32 フォルダにあります。
さて、英語版の CSRSS.EXE の中身を grep などで検索してみると、 どこにも「The memory could not be "read".」 というような文字列がないことがわかります。 この場合、この EXE ファイル以外の何らかのファイルにこの文字列が あるということになります。 どのファイルにあるのかははっきりとはわからないのですが、 とりあえずはこの EXE ファイルと関係が深いファイルということで、 この EXE ファイルがリンクしている DLL を調べてみることにします。
EXE ファイルがどんな DLL をリンクしているかを 調べる目的には、Visual Studio に付属する dumpbin ユーティリティの /dependents オプションが便利です。これを使うと次のような出力が得られます:
c:\home> dumpbin /dependents \winnt\system32\CSRSS.EXE
Microsoft (R) COFF/PE Dumper Version 7.00.9466
Copyright (C) Microsoft Corporation. All rights reserved.
Dump of file \winnt\system32\CSRSS.EXE
File Type: EXECUTABLE IMAGE
Image has the following dependencies:
CSRSRV.dll
ntdll.dll
Summary
1000 .reloc
1000 .rsrc
1000 .text
これにより、CSRSS.EXE が CSRSRV.dll と ntdll.dll という二つの DLL をリンクしていることが判明します。
ここでこの二つのファイルの中を検索すると、ntdll.dll が 上記の文字列を含んでいることがわかります。
より詳細に知るために、この DLL を Visual Studio の統合環境の リソースエディタで開いてみます:
(Visual Studio .Net ではデフォルトでリソースエディタが開きますが、 古いバージョンの Visual Studio ではそうではないため、 プルダウンメニューで明示的にリソースエディタで開くよう指定します)
さて、開いてみると、ストリングテーブルなどはなく、 代わりに謎のバイナリファイルが埋めこまれていることがわかります:
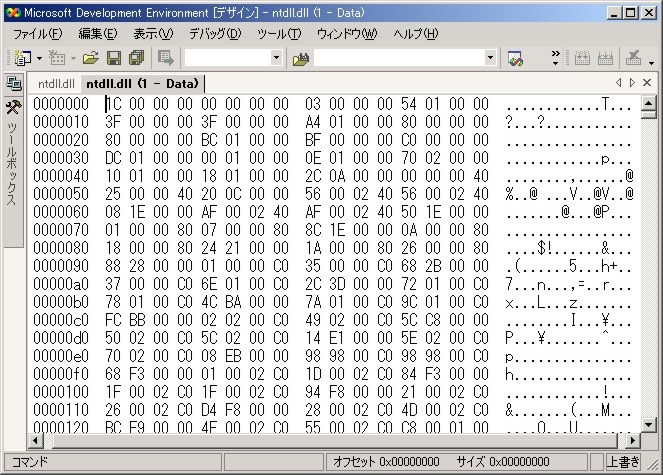
これはおそらく、Visual Studio の mc.exe というツールでコンパイルされた、 メッセージカタログのバイナリであると推測されます。 現在では通常、文字列を保持するためにはリソースのストリングテーブルを 使いますが、昔はこういう風にしてメッセージを保持していました。
さて、このカタログバイナリを検索すると、次のような箇所があります:
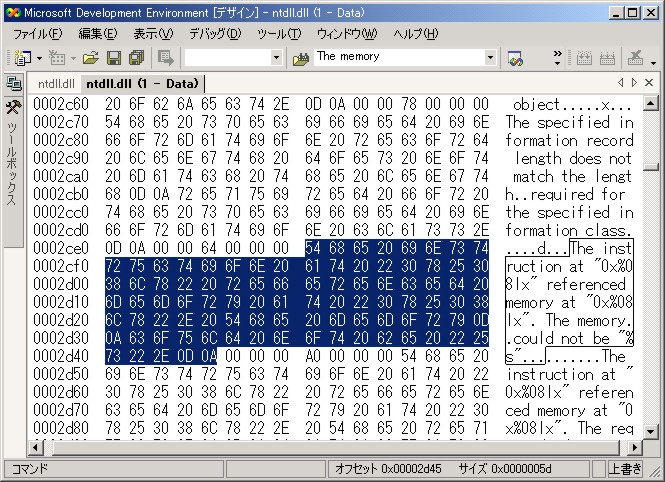
これが目的の文字列に他なりません。日本語版の ntdll.dll では、 次のように UTF-16 で表現されています:
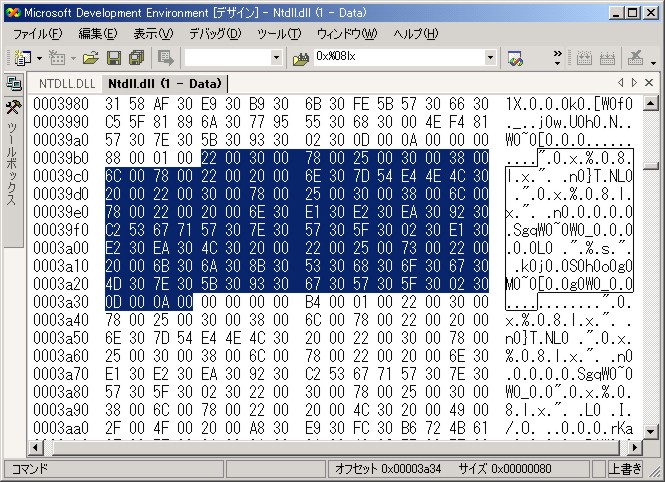
このように、メッセージをカタログファイルに分離しておき、 カタログファイルだけを入れ換えることによって、 プログラム本体のソースを変更することなしに表示言語を切り替えるという方法は、 国際化でよく使われる手法です。
この両者を観察すると、次のことがわかります:
これらの文字列は、C 言語の printf 形式のフォーマット文字列であり、 両方とも %lx と %s という二つの変換子を含む。
この二つの変換子の登場する順番は同じである。
"read" や "written" はカタログ化されていない。
このことから推測されることは、
このメッセージは、直接 printf ファミリ関数のフォーマット文字列として 渡されるのであろう。よって、このメッセージでは 英語版と同じ順序で %lx と %s の二つを登場させる必要がある。
"read" や "written" は、 %s を置換する文字列としてソース中に直接記述されているようだ。 よって、プログラム本体のソースを変更することなしに これらの文言を変更することはできない。
ということであり、このことから導かれる結論は、
日本語化担当者には、 プログラム本体のソースを変更する手段および権限が与えられていないか、 与えられていても非常に制限されている。
ということですね。政治の世界ではよくあることです。
とどのつまり、「"read" になることはできませんでした」という珍妙な日本語は、 このような制限のもとで如何にしてこのメッセージを表示するかということに 頭をひねった日本語化担当者の苦肉の策だったといえます。 決して誤訳ではないのです。
この話は、メッセージカタログという国際化の仕組みを利用しているにもかかわらず、 その利用法が不適切だったために ちゃんとしたローカライゼーションができなかった例ということになります (「『gmake: 入りますディレクトリ』のひみつ」 という文章はもう必要ありませんよね?)。 ソフトウェアのローカライゼーションというのは、 政治的にも、技術的にも、いろいろと難しい問題を含んでいることがわかりますね。 このことは以前に BSD マガジンでも書きましたし、あるいは SRC が出している 「ソフトウェアローカリゼーション実践ハンドブック」 という本を読むと、先人の苦労を垣間見ることができます。